





Dans cette phase de théorie, je vais essayer de vous expliquer le principe d’un réseau de neurones sans plonger dans les formules mathématiques. Je vais vous donner des liens si vous souhaitez aller plus loin.
LE PRINCIPE :
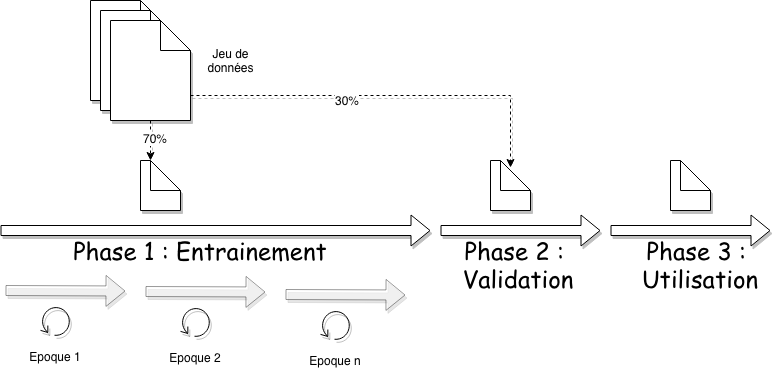
Ces 3 phases participent à la mise en œuvre d’un réseau de neurones. Lors des deux premières phases, nous allons utiliser le même jeu de données.
Nous allons séparer le jeu de données en deux :
- 80% du jeu sera utilisé pour la phase d’entrainement.
- 20% du jeu sera utilisé pour valider les résultats du réseau.
LES DONNÉES :
Le jeu de données est très important pour assurer un bon apprentissage. Dans le cadre de cet exercice, je vais utiliser un jeu de données bancaire anonymisé disponible à titre de formation sur internet.
source : https://archive.ics.uci.edu/ml/datasets/Bank+Marketing
Ce jeu de données comporte
- 20 colonnes utiles à la qualification du client
- Une colonne avec la donnée que nous allons essayer de prédire : Le client a t’il réalisé un dépôt à terme.
Le dépôt à terme est une expression utilisée dans le langage bancaire et financier faisant référence à une somme d’argent bloquée sur un compte et produisant des intérêts. Le taux d’intérêt sur le dépôt à terme fait l’objet d’une négociation entre la banque et son client.
https://droit-finances.commentcamarche.com/faq/23721-depot-a-terme-definition
Toutes les colonnes ne seront pas utiles. Il faut veiller à ne pas injecter lors de l’entrainement des données inutiles pouvant perturber le système.
Je vous montrerai la mise en forme des données dans le prochain article.
LA PHASE D’ENTRAINEMENT
C’est lors de cette phase que toute la magie se produit :-).
D’abord… comment représenter un réseau de neurones ?
Un réseau de neurones est souvent schématisé de la façon suivante :
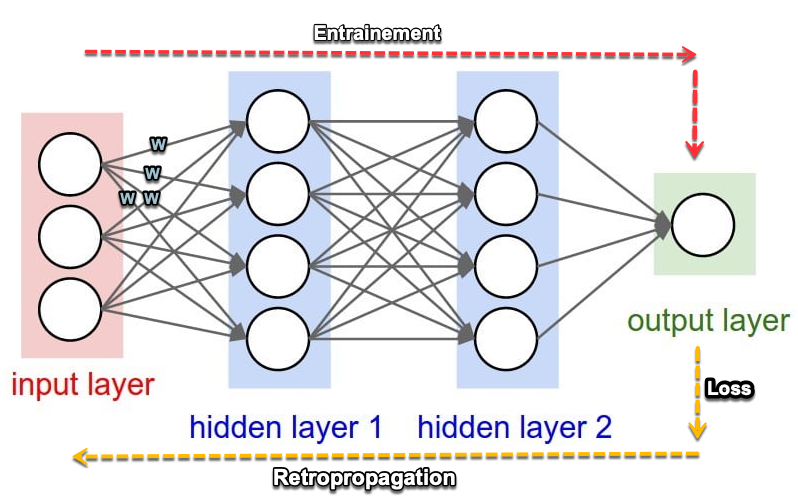
Chaque rond correspond à un neurone.
Nous distinguons 3 types de couches de neurones :
- La couche d’entrée.
- Les couches cachées.
- La couche de sortie.
Les neurones de chaque couche sont liés à chaque neurone de la couche suivante par un liaison pondérée (w). Dans notre prototype, nous allons lors du setup, positionner des poids de façon aléatoire.
LA COUCHE D’ENTRÉE.
La couche d’entrée fait le lien entre chacune des données à traiter par le réseau de neurones et les couches cachées. Comme dans toutes les couches, les neurones sont liés a chaque neurones de la couche suivante. Ces liaisons disposent d’un poids (w) permettant de pondérer la valeur.
Les neurones appliquent une fonction mathématique basique. Elle s’appelle : fonction d’activation du neurone.
Il en existe plusieurs, pour ma part j’utilise en général RELU (j’ajoute en fin d’article de la lecture sur le sujet). Relu, est une fonction de redressement, elle va suivre la courbe suivante :

Ne cherchez pas encore à comprendre le fonctionnement détaillé de RELU. Gardez cette information, vous comprendrez mieux dans les articles qui suivent.
LES COUCHES CACHÉES.
Les neurones des couches cachées fonctionnent comme les neurones d’entrée. Ils contiennent une fonction d’activation, et sont liés à chaque neurone de la couche suivante.
Pour notre test, afin de conserver un réseau capable de tourner dans un temps acceptable, j’ai décidé arbitrairement d’utiliser deux couches cachées de neurones. C’est en générale la valeur de départ de mes prototypes, il suffit ensuite de tester avec plus ou moins de couches pour essayer d’obtenir le meilleur ratio « temps de calcul / % de performance ».
COMMENT ESTIMER LE NOMBRE DE NEURONES D’UNE COUCHE CACHÉE ?
Il faut tester…
Pour mes prototypes, et pour conserver des temps de calculs acceptables, j’applique comme base de départ le calcul suivant :
Nb de neurones = Ceil (Nb_Neurones_Entrée / 2)
Nombre de neurones de la couche d’entrée, divisé par deux, arrondi à l’entier supérieur.
J’applique également pour un prototype, une configuration de deux couches cachées.
LA COUCHE DE SORTIE.
La couche de sortie dépend du nombre de valeur que nous souhaitons prédire. Dans notre cas, nous n’allons prédire qu’une donnée… donc un neurone de sortie.
Plus le nombre de données en sortie augmente, plus il faudra augmenter le nombre de neurones et de couches cachées.
Notre neurone de sortie va également contenir une fonction d’activation, mais cette fois ci, elle sera différente. Pour obtenir une probabilité d’appartenance de nos données d’entrées au groupe, nous utiliserons la fonction ‘Sigmoïd’

Vous trouverez de la lecture en fin d’article sur les fonctions d’activations.
LA RÉTRO-PROPAGATION
A chaque fin de cycle, le réseau de neurones va évaluer l’erreur qu’il a avec les données attendues. Une fois cette erreur évaluée, le réseau va passer en phase de rétro-propagation.

Cette phase va permettre au réseau d’adapter, via l’application de fonctions mathématiques, les poids des liaisons entre chaque neurone.
Une fois cette étape terminée, le réseau est donc modifié, il va pouvoir continuer avec les données suivantes.
LES ÉPOQUES
Une époque correspond à un cycle pendant lequel le réseau va s’entrainer sur le jeu de données d’entrainement complet.
Le réseau va donc faire passer les données autant de fois que nous demandons d’époques.
L’augmentation ou la diminution du nombre d’époques va influencer fortement l’apprentissage du réseau de neurones artificiels.
Dans notre prototype, nous utiliserons 100 époques. Au-delà de cette valeur, notre réseau ne progresse pas vraiment.
Il faut effectuer des essais pour trouver une valeur qui soit un bon rapport « temps d’entrainement / résultat ».
LA PHASE DE VALIDATION
Lors de la phase de validation, nous allons faire passer dans le réseau les 20% du jeu de données non utilisées.
Nous gardons pour nous les valeurs des résultats de chaque ligne, et nous allons les confronter aux résultats du réseau pour en valider la performance.
POURQUOI POURRIONS-NOUS AVOIR DES RÉSULTATS MOINS EFFICACES QUE LORS DE L’ENTRAINEMENT ?
Certaines configurations (nombres de couches, fonctions d’activation, jeux de données, nombre de neurones…) conduisent à des résultats instables, voir du surentrainement.
Il est possible d’avoir un réseau ayant de très bonnes performances sur le jeu d’entrainement, mais incapable d’appliquer ces résultats à d’autres données.
C’est une version numérique de l’entêtement :-). Le réseau doit explorer différentes options et ne surtout pas se conforter trop rapidement dans une piste, qui ne serait pas une généralisation efficace.
LE DROUPOUT…
Une des protections lors de l’entrainement est la méthode du ‘dropout’. Cette action consiste à détruire un certain nombre de neurones afin pour permettre au réseau d’explorer de nouvelles solutions.

LA MATRICE DE CONFUSION
Lors de la validation, nous allons utiliser une matrice de confusion.
La matrice de confusion est une méthode pour évaluer les résultats de façon très simple.
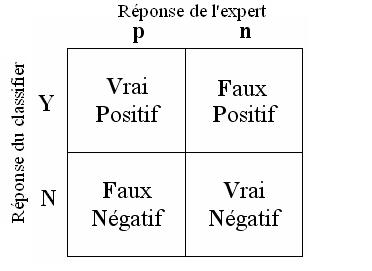
Nous prendrons les valeurs ‘Vrai’ positif ou négatif que nous diviserons par le nombre d’entrées du fichier, pour obtenir le pourcentage de réussite du modèle.
La théorie de la matrice de confusion très complexe, je vous invite à regarder en annexe les liens pour en apprendre d’avantage.
ENFIN L’UTILISATION
Simple, nous allons proposer à notre programme d’injecter des valeurs pour obtenir des estimations de sortie. Le résultat sera un pourcentage d’appartenance ‘probable’ de nos données à l’ensemble de données évaluées.
Dans notre cas, un pourcentage d’appartenance probable au groupe de client ouvrant des dépôts à terme.
J’ai fait l’impasse sur quelques notions et termes. Vous les découvrirez lors de la pratique.
Un peu de pratique ??? Allons à l’article suivant.
ANNEXES
- Les fonctions d’activations : https://fr.wikipedia.org/wiki/Fonction_d%27activation
- Utilisation de Sigmoid : https://towardsdatascience.com/multi-layer-neural-networks-with-sigmoid-function-deep-learning-for-rookies-2-bf464f09eb7f
- Matrice de confusion : https://en.wikipedia.org/wiki/Confusion_matrix
- Formation en français top: https://www.udemy.com/le-deep-learning-de-a-a-z/learn/v4/


[…] Lire la première partie. […]