





Objectif : Mettre en œuvre un réseau de neurones. Nous allons entrainer ce réseau avec un fichier bancaire indiquant si les clients ont ouvert un « dépôt à terme ».
Source du dataset : https://archive.ics.uci.edu/ml/datasets/Bank+Marketing
Le fichier d’entrée est un véritable fichier bancaire anonymisé datant de 2012. Il est très important d’avoir comme source un fichier de données cohérent, sinon, le réseau n’apprendra pas correctement.
Les frameworks que nous allons utiliser :
- Python.
- SciKit Learn (sklearn): https://scikit-learn.org/stable/
- Keras: https://keras.io/
LES ÉTAPES DU PROGRAMME :

LECTURE DES DONNÉES
Nos données contiennent les informations suivantes :
J’ai retiré du fichier les données que je considère comme inutile. Par exemple, le mois du dernier email reçu… Inutile dans notre contexte.
- age (numeric)
- job : type of job (categorical: ‘admin.’,’blue-collar’…)
- marital : marital status
- education
- default: has credit in default? (categorical: ‘no’,’yes’,’unknown’)
- housing: has housing loan? (categorical: ‘no’,’yes’,’unknown’)
- loan: has personal loan? (categorical: ‘no’,’yes’,’unknown’)
- duration: last contact duration, in seconds (numeric).
- campaign: number of contacts performed during this campaign.
- pdays: number of days that passed by after the client was last contacted
- previous: number of contacts performed before this campaign and for this client (numeric)
- poutcome: outcome of the previous marketing campaign
- emp.var.rate: employment variation rate
- cons.price.idx: consumer price index
- cons.conf.idx: consumer confidence index
- euribor3m: euribor 3 month rate
- nr.employed: number of employees
- y – has the client subscribed a term deposit? (binary: ‘1’,’0′)
CHARGEMENT DES DONNÉES.
# ANN : Artificial Neural Network DEMO
# STEP 1 : READING INPUT DATA
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('bank-additional-full.csv', sep=';')
X = dataset.iloc[:, 0:16].values
y = dataset.iloc[:, 16].valuesNous séparons les données en deux jeux :
- X => Les données d’entrées colonnes 1 à 17.
- y => Les données de sortie colonne 18.
ENCODAGE DES TEXTES
# Encoding categorical data
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
# Not required, this is an issue with my laptop CPU and Keras Libimport osos.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# STEP 2 : ENCODING LABEL TO NUMERIC VALUES, FITTING for INPUT
labelencoder_X_1 = LabelEncoder()
X[:, 1] = labelencoder_X_1.fit_transform(X[:, 1])
labelencoder_X_2 = LabelEncoder()
X[:, 2] = labelencoder_X_2.fit_transform(X[:, 2])
labelencoder_X_3 = LabelEncoder()
X[:, 3] = labelencoder_X_3.fit_transform(X[:, 3])
labelencoder_X_4 = LabelEncoder()
X[:, 4] = labelencoder_X_4.fit_transform(X[:, 4])
labelencoder_X_5 = LabelEncoder()
X[:, 5] = labelencoder_X_5.fit_transform(X[:, 5])
labelencoder_X_6 = LabelEncoder()
X[:, 6] = labelencoder_X_6.fit_transform(X[:, 6])
onehotencoder = OneHotEncoder(categorical_features = [1,2,3,4,5,6])
X = onehotencoder.fit_transform(X).toarray()Le réseau de neurone n’est pas capable de travailler sur des chaînes de caractères. Il faut les convertir en valeurs numériques.
C’est le rôle du labelencoder. J’ai représenté sur le schéma suivant son action :

Une fois ces valeurs encodées, il faut les séparées.
Si nous conservons toutes les valeurs dans une seule colonne avec des valeurs allant de 0 à N, le réseau risque d’en comparer les valeurs. Ça n’a pas de sens de comparer une pomme encodée par 2, et une orange en 0.
C’est le rôle du OneHotEncoder. Son action va séparer chaque valeur par une nouvelle colonne contenant des valeurs binaires (points 2 & 3).
A ce stade, nos données d’entrées n’ont plus 15 colonnes… mais 43. Ce sont les neurones d’entrés de notre réseau (point 4)
SPLIT DES JEUX D’ENTRAINEMENT ET DE TEST
A ce stade, nous pouvons séparer le jeu de données en deux :
- 80% pour l’entrainement.
- 20% pour le test.
# STEP 4 : SPLITTING DATA INTO TWO DATASET TRAIN & TEST
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)SCALING DES DONNÉES
Cette étape est essentielle, elle permet de mettre sur une échelle commune toutes les données. Le réseau pour fonctionner utilise des fonctions d’activations, des coefficients et des fonctions mathématiques, qui pour obtenir un résultat, doivent recevoir des données dans une plage de valeurs normalisées.
# STEP 5 : SCALING DATAS
from sklearn.preprocessing import Standard
Scalersc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)CRÉATION ET ENTRAINEMENT DU RÉSEAU
Import de Keras, pour initialiser le réseau.
# STEP 6 : BUILDING THE ANN
# Importing the Keras libraries and packages
import kerasfrom keras.models
import Sequentialfrom keras.layers
import DenseCréation d’une instance du réseau de neurones.
# Initialising
myann = Sequential()Ajout de la couche d’entrée avec :
# Adding input layer and first hidden layer
myann.add(Dense(units = 10, kernel_initializer = 'uniform', activation = 'relu', input_dim = 43))- 43 Neurones pour la couche d’entrées. Ils seront automatiquement connectés à une colonne de nos données.
- 10 Neurones pour la première couche cachée.
- Fonction d’activation des neurones : RELU (https://en.wikipedia.org/wiki/Rectifier_(neural_networks))
- Initialisation des poids entre les neurones : ‘uniform’
Création de la seconde couche cachée :
# Adding a second hidden layer
myann.add(Dense(units = 10, kernel_initializer = 'uniform', activation = 'relu'))Seconde couche cachée. Les paramètres sont identiques, sauf que nous n’indiquons pas la source, le réseau ajoute simplement cette couche à la couche précédente.
Ajout de la couche de sortie.
# Adding the output layer
myann.add(Dense(units = 1, kernel_initializer = 'uniform', activation = 'sigmoid'))- Un neurone de sortie.
- Fonction d’activation ‘sigmoid’.
- Toujours une initialisation des poids type ‘uniform’.
Compilation du réseau de neurones.
# Compiling the ANN
myann.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])- Optimisation de l’erreur via l’algorithme de retro-propagation ‘adam’. C’est un dérivé de l’algorithme du Gradient Stochastique : https://machinelearningmastery.com/adam-optimization-algorithm-for-deep-learning/
- Calcul de la perte via l’algorithme : Binary CrossEntropy : https://ml-cheatsheet.readthedocs.io/en/latest/loss_functions.html
- Métrique à mesurer : Accuracy (précision).
Enfin, nous allons entrainer le réseau.
# Fitting the ANN to the Training set
myann.fit(X_train, y_train, batch_size = 10, epochs = 100)- X_Train : Colonnes d’entrées du réseau.
- y_train : Valeurs de sorties attendues.
- batch_size : Nombre de valeurs à traiter avant de passer au calcul d’erreur et rétro-propagation.
- Epochs : Nombre d’époques de notre entrainement.
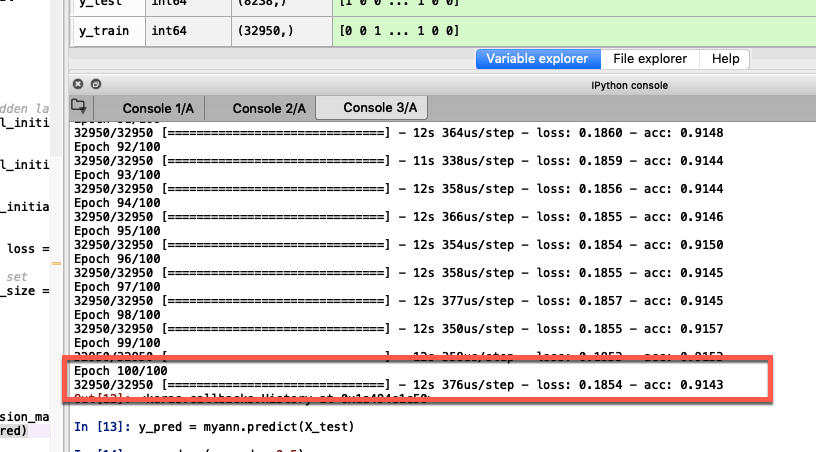
La console de spyder affiche les informations suivantes :
- Epoch 100/100. C’est la dernière époque de l’entrainement.
- acc: 0.91 => 91% de réussite.
91%, c’est un très bon résultat pour un réseau aussi simple tournant sur mon portable.
VALIDATION DU RÉSEAU
D’abord, nous calculons les résultats pour chaque ligne de notre jeu de test :
# Predicting the Test set results
y_pred = myann.predict(X_test)y_pred = (y_pred > 0.5)Nous décidons qu’une prédiction avec un pourcentage supérieur à 50% est considérable comme vrai.
Ensuite, nous utilisons la matrice de confusion (voir l’article précédent), pour valider la performance :
# Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)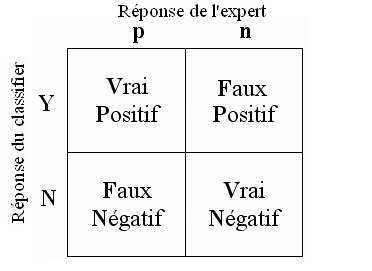
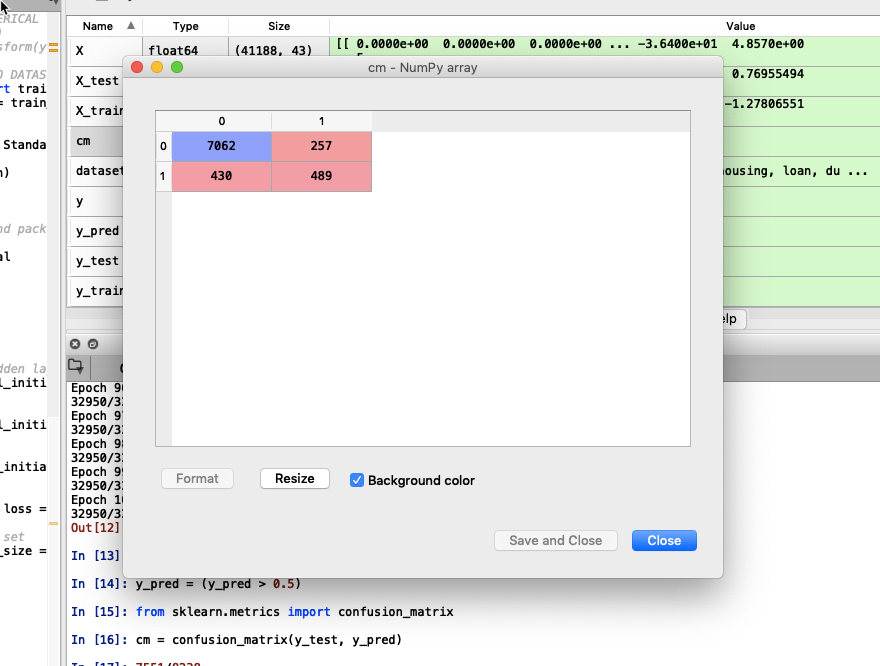
Le résultat est : ( ( 7062 + 489 ) / ( 7062 + 489 + 257 + 430 ) ) * 100 = 91,66%

