





Les réseaux de neurones sont au cœur de l’intelligence artificielle moderne. Ils permettent aux machines d’apprendre à partir de données, et se retrouvent partout : assistants vocaux, traduction automatique, reconnaissance d’images, recommandations ou génération de texte.
Pour comprendre comment ces systèmes fonctionnent — et leurs limites — un petit détour historique aide à poser les bases.
Si vous n’avez pas le temps de lire, cet article est résumé en vidéo :
Sinon, bonne lecture…
Une brève histoire de l’intelligence artificielle
L’IA naît officiellement en 1956 à la conférence de Dartmouth : des chercheurs imaginent qu’une machine pourra un jour simuler l’intelligence humaine.
Dans les années 1960, apparaît le perceptron, ancêtre des réseaux de neurones. L’idée est simple : prendre des entrées numériques et produire une décision. Mais l’époque manque de données et de puissance de calcul. Les progrès ralentissent.
C’est le premier hiver de l’IA dans les années 1970 : financements en baisse, recherche en pause. Une relance arrive dans les années 1980 grâce à un concept clé : la rétropropagation. Mais la dynamique retombe encore à la fin de la décennie.
Tout change dans les années 2010 car trois facteurs s’alignent :
- Nous avons des quantités de données massives
- Les GPU sont capables de calculer rapidement
- Les réseaux sont de plus en plus rapides & puissants
À partir de 2020, l’IA générative devient accessible au grand public. Les réseaux de neurones entrent dans une nouvelle phase : adoption massive et usages concrets. C’est l’avenement d’OpenAI, Mistral, Grok…
C’est quoi un réseau de neurones ?
Reprenons à la base pour comprendre ce que nous faisons actuellement! Un réseau de neurones est un ensemble de petites unités de calcul appelées neurones artificiels, organisées en couches et reliées entre elles.
Chaque neurone est en charge d’un calcul très simple. Mais lorsqu’on en combine des milliers (ou des millions…), un comportement complexe apparait.
L’idée est simple… un neurone transforme des valeurs d’entrée en une valeur de sortie.
Un neurone : c’est une mini-fonction
Un neurone reçoit une ou plusieurs entrées :
- … (pixels, mesures, mots transformés en nombres)
Chaque entrée a un poids :
- …
Le poids indique l’importance de l’entrée.
Le neurone calcule une somme pondérée :
Puis il ajoute un biais , qui permet de “décaler” son comportement :
Enfin, il applique une fonction d’activation :
Cette activation joue un rôle crucial : elle permet au réseau de modéliser des relations complexes, pas seulement des additions. Elle décide de l’activation du neurone et de son rôle dans le résultat.
Extrait de Wikipédia
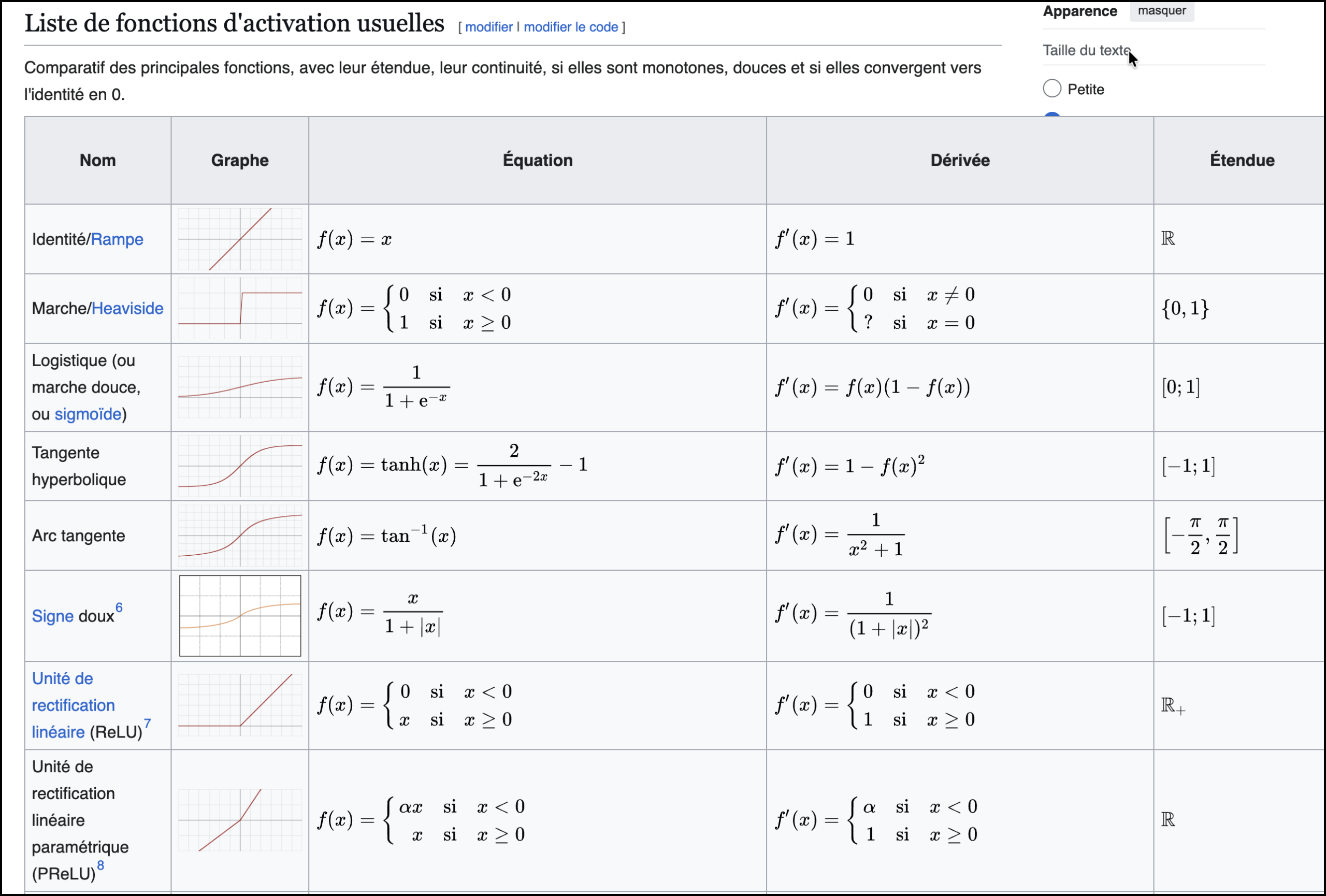
En résumé :
✅ Entrées → pondération → somme → activation → sortie
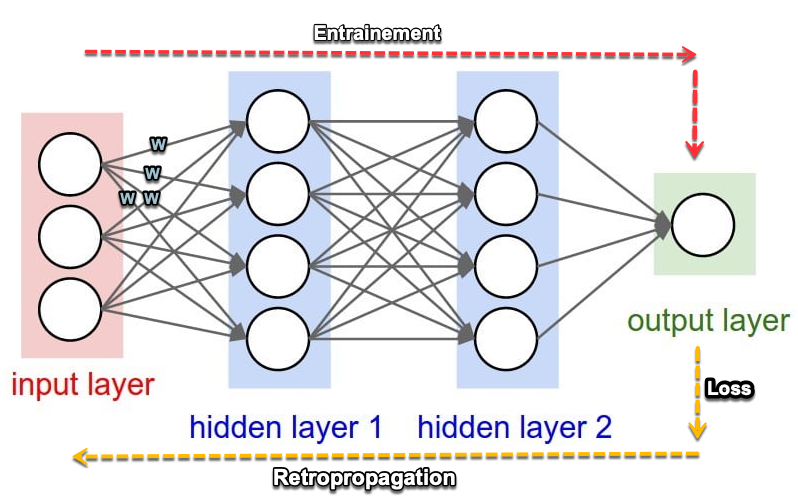
Réseau = neurones en chaîne
Un réseau de neurones est un empilement de couches :
- couche d’entrée : reçoit les données
- couches cachées : transforment l’information
- couche de sortie : produit le résultat
En vision par exemple, le réseau peut apprendre progressivement :
- bords et contrastes
- motifs (formes, textures)
- objets (“chat”, “voiture”, etc.)
Pourquoi les poids sont essentiels ?
Les poids sont ce que le modèle apprend.
Ils constituent littéralement sa “mémoire”.
Quand un réseau apprend, il n’ajoute pas des règles explicites,
Il ajuste ses poids pour produire de meilleures sorties et s’approcher via un calcul statistique du résultat attendu.
Schéma simple (version web)

Vous connaissez le jeu de Plinko ?

Un reseau de neurone, c’est un peu comparable à un jeu de Plinko. Vous connaissez ce jeu où une bille tombe sur un plateau rempli de clous.
À chaque rebond, elle dévie légèrement… et finit dans une case en sortie du jeu.
Imaginez une donnée en entrée du réseau de neurones, qui traverse les couches, est modifiée par les neuronnes pour arriver en sortie à un valeur ciblée. Le travail de notre reseau est de reussir à s’adapter pour faire tomber la bille toujours dans la bonne case, celle qui permet de gagner!
Effectivement :
- chaque interaction locale est simple
- mais la somme des rebonds produit un résultat global
Un réseau de neurones fonctionne de manière similaire :
- chaque neurone fait un petit calcul local
- aucun neurone ne “comprend” le résultat final
- mais leur combinaison produit une sortie cohérente
Et surtout : modifier le plateau de Plinko change la trajectoire.
Dans un réseau, modifier les poids et la fonction d’activation change le comportement du modèle.
✅ À retenir — Réseau de neurones
- Un neurone = une fonction : somme pondérée + activation
- Les poids déterminent l’importance des entrées
- Apprendre = ajuster les poids
- Beaucoup de neurones simples → un comportement complexe
Comment un réseau de neurones apprend-il ?
Pour apprendre, le réseau fait des prédictions sur notre jeu de données, puis compare ses résultats à la bonne réponse.
La différence est mesurée par une fonction de perte (loss).
La perte (loss) : mesurer l’erreur
👉 La perte est un chiffre qui mesure “à quel point le réseau se trompe”. Je vous passe les algos de calcul de la perte qui nécessitent un article à eux seuls.
- loss élevée → mauvaise prédiction
- loss faible → bonne prédiction
L’objectif de l’entraînement est simple : ✅ faire diminuer la perte
Comment ajuster les poids efficacement ?
Une fois la perte calculée, le réseau doit savoir comment modifier les poids pour l’améliorer.
C’est le rôle de la descente de gradient. Là aussi, sachez que cet algorythme à pour objectif de trouver la meilleure valeur de poids pour chaque neurone.
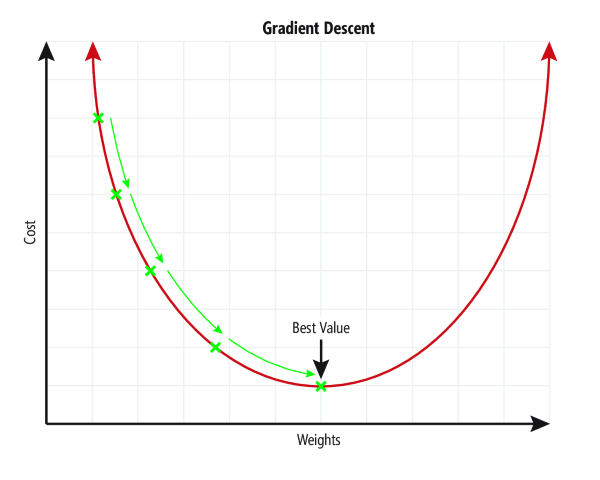
L’explication détaillée est assez complexe mais visible en ligne, sur Wikipedia par exemple : https://fr.wikipedia.org/wiki/R%C3%A9tropropagation_du_gradient
Notez que cet algo à un rôle crucial à cause de la taille des pas pour obtenir la meilleure valeur (voir la courbe).
En effet :
- trop petit → stable, mais lent
- trop grand → instable, le modèle “saute” autour de la solution
Voila, une fois ces informations comprises, nous commençons à entrainer le modèle sur le jeu de données. nous allons lui faire traiter de nombreuses fois pour qu’il puisse adapter le reseau et obtenir ce qui lui semble la meilleure solution. Ces multiples passage du jeu de données, c’est ce qu’on appelle le nombre d’époques de l’entrainement.
Une époque (epoch)
Une époque = un passage complet sur toutes les données d’entraînement.
Exemple :
- 10 000 images
- 20 époques
- le modèle a vu ces images 20 fois
✅ Plus d’époques = plus d’occasions d’apprendre
⚠️ Trop d’époques = risque de surapprentissage
En pratique, on ne traite pas toutes les données d’un coup.
On les découpe en mini-batchs :
- après chaque mini-batch, les poids sont ajustés
- une époque correspond à un parcours complet de tous les mini-batchs
Train / Validation / Test
Il est temps de vérifier la qualité de notre travail. Afin de vérifier si le modèle est réellement bon, on divise les données en trois jeux:
- Train : le modèle apprend, nous fournissons au modèle les questions et les réponses.
- Validation : on vérifie pendant l’entraînement, nous fournissons toujours les question et les réponses.
- Test : évaluation finale, sur des données jamais vues, nous ne fournissons que les questions que nous comparons aux reponses attendues.
- train = exercices
- validation = examens blancs
- test = examen final
Cette étape est essentielle pour détecter le surapprentissage ou la surspécialisation d’un modèle.
J’avais lu une anecdote sur l’entrainement d’un modèle dont le rôle était de detecter des images avec des husky. Lors de l’entrainement le résultat était excellent. Lors des tests, le resultat etait toujours excellent. En production le devenait vraiment mauvais.
Après investigation, la raison était très simple. Le réseau n’avait pas apprit à reconnaitre une image de Husky, mais une image avec de la neige! Effectivement, le jeu d’entrainement, mal équilibré, contenait énormément d’image enneigées.
Ce type de problème trouve très souvent sa source dans votre jeu de données. Attention à ne pas ajouter involontairement de biais d’interpretation dans vos données.
✅ À retenir — Entraînement
- La loss mesure l’erreur
- La descente de gradient ajuste les poids
- Le learning rate contrôle la vitesse
- Une époque = un tour complet sur toutes les données
- Train/Val/Test permet de vérifier la généralisation
Le dropout : éviter qu’un réseau se spécialise trop
Il existe tout de même une technique pour limiter l’effet de sur-specialisation d’un réseau, c’est le dropout. Un réseau peut devenir excellent sur les exemples qu’il a vus… mais mauvais sur des cas nouveaux.
C’est le surapprentissage (overfitting).
Le dropout limite ce risque :
- pendant l’entraînement, on désactive aléatoirement certains neurones
- le réseau doit donc apprendre à être robuste, sans dépendre de quelques neurones “stars”
Enfin, il ne faut pas confondre sur-spécialisation d’un réseau et hallucination. Ce sont deux choses très différentes. Meme si nous arrivons à minimiser l’hallucination, cette dernière est inhérente au fonctionnement statistique des modèles d’IA.
Les hallucinations en intelligence artificielle
Une hallucination survient lorsqu’une IA produit une réponse incorrecte, tout en étant très convaincante.
Ce n’est pas un bug : ces modèles prédisent ce qui est probable, pas ce qui est vérifié.
Tableau récapitulatif
| Type | Ce que ça signifie | Exemple | Pourquoi |
|---|---|---|---|
| Factuelle | l’IA invente un fait | “Napoléon est mort en 1842” | pas de vérification |
| Raisonnement | logique incorrecte | conclusion fausse | imitation de schémas |
| Sources | fausses références | “article MIT 2021” | génération plausible |
Conclusion pratique :
👉 une IA peut accélérer un travail, mais elle ne doit pas être considérée comme une source de vérité sans contrôle.
IA générative : comment le texte devient des chiffres (tokens)
Une IA ne manipule pas directement des mots : elle manipule des nombres.
Pour cela, le texte est découpé en tokens :
👉 un token peut être un mot, ou un morceau de mot. C’est suivant les fournisseurs un nombre de caractères.
Exemples :
- “chat” peut être 1 token
- “anticonstitutionnellement” peut être plusieurs tokens
Ensuite, le modèle prédit token après token.
C’est ce qui explique :
- la limite de longueur exprimée en nombre de tokens
- pourquoi certains mots longs coûtent plus “cher”
- pourquoi la génération est progressive
✅ À retenir — Texte et tokens
- Le texte est découpé en tokens (pas forcément des mots)
- Le modèle prédit le prochain token, puis le suivant
- La limite d’un modèle se mesure souvent en nombre de tokens
Paramètres : pourquoi on parle de “modèle à X milliards”
Les poids qu’un modèle apprend sont appelés paramètres.
👉 Un modèle à 7 milliards de paramètres possède environ 7 milliards de poids ajustables.
Plus il y a de paramètres :
- plus le modèle peut apprendre des structures complexes
- mais plus il coûte cher en mémoire, calcul et énergie
Et attention : Comme toujours, ce n’est pas juste une question de taille.
La qualité des données et l’entraînement comptent énormément.
Quel avenir pour l’IA ?
Nous avons déjà passé plusieurs périodes creuses pour l’IA. Un nouvel hiver de l’IA n’est pas impossible, mais il serait différent des précédents.
Aujourd’hui, l’IA est intégrée à des usages concrets et crée une valeur tangible. Les défis actuels concernent davantage l’énergie, les coûts, la disponibilité des données et la régulation que la faisabilité technique.
Cependant, il faut noter qu’au moment ou je rédige cet article, aucune des société gérant les principaux modèles n’a trouvé de rentabilité (OpenAI, Mistral, Anthropic avec les Claude…). Toutes perdent des sommes colossales liées à des investissements massifs.
Un domaine pourrait toutefois transformer l’avenir : l’informatique quantique. À long terme, elle pourrait accélérer certains calculs d’apprentissage et explorer des combinaisons aujourd’hui inaccessibles et ouvrir la voie à de nouvelles générations de modèles. En 2025, cette technologie reste expérimentale, mais elle représente une piste sérieuse pour dépasser certaines limites actuelles.
Des sociétés comme OVH misent énormément d’argent sur le sujet. C’est une fuite en avant de la performance permettant une évolution majeure dans les domaines de la sécurité et de l’IA.
Je termine cet article par un petit glossaire, toujours très pratique pour mettre les bons mots sur les bons concepts.
📌 Glossaire (pour fixer les idées)
- Neurone artificiel : unité de calcul qui transforme des entrées en une sortie.
- Poids / paramètres : valeurs apprises qui déterminent l’importance des entrées.
- Biais : valeur ajoutée pour ajuster le seuil de déclenchement.
- Activation : fonction qui rend le réseau capable d’apprendre des relations complexes.
- Loss : mesure numérique de l’erreur.
- Descente de gradient : méthode pour ajuster les poids afin de réduire la loss.
- Learning rate : taille des corrections appliquées aux poids.
- Époque : passage complet sur toutes les données d’entraînement.
- Mini-batch : petit lot de données utilisé pour entraîner.
- Train / Validation / Test : découpage des données pour mesurer la généralisation.
- Overfitting : modèle trop spécialisé sur ses données d’entraînement.
- Dropout : technique qui désactive des neurones pour réduire l’overfitting.
- Token : unité de découpage du texte (mot ou morceau de mot).
- Hallucination : réponse fausse mais plausible.

